|
I am a PhD Candidate in Computer Science, Viterbi School of Engineering, Unviersity of Southern California, advised by Prof. Stefanos Nikolaidis. Previously I worked at Vision and Graphics Lab with Prof. Hao Li. My research interests contain Computer Vision, Generative Models and Embodied Agents. In particular, I am interested in using AI-generated content for Embodied Planning and Content Creation. I am actively seeking full-time opportunities starting in 2026. Please feel free to reach out if you think my background could be a good fit. Email / Resume / Google Scholar / Linkedin |

|
|
Reviewer of the following conferences/journals: SIGGRAPH, CVPR, ECCV, ICCV, ACM Multimedia(MM), ICML, NeurIPS, WACV |
|
TikTok
MBZUAI
TikTok
|
|
Teaching Assistant, CSCI 585 Database Systems
|
|
|
|
Yuming Gu, Yizhi Wang, Yining Hong, Yipeng Gao, Hao Jiang, Angtian Wang, Bo Liu, Nathaniel S. Dennler, Zhengfei Kuang, Hao Li, Gordon Wetzstein, Chongyang Ma Arxiv, 2025[PDF][Page] Area: Embodied AI, Video Generation Model We introduce ENVISION, a novel framework that generates physically plausible planning videos with precise instruction following, enabling direct execution on robotic systems. |
|
|
Heyuan Li, Huimin Zhang, Yuda Qiu, Zhengwentai Sun, Keru Zheng, Lingteng Qiu, Peihao Li, Qi Zuo, Ce Chen, Yujian Zheng, Yuming Gu, Zilong Dong, Xiaoguang Han ICLR, 2026[PDF][Page] Area: Area: Novel View Syntehsis, 3D GAN, Head we propose a novel view-invariant semantic feature as the conditioning input, thereby decoupling the generative capability of 3D heads from the viewing direction. |
|
|
Yuming Gu, Phong Tran, Yujian Zheng, Hongyi Xu, Heyuan Li, Adilbek Karmanov, Hao Li. CVPR, 2025 [PDF][Page][Code] Area: Novel View Syntehsis, Diffusion Model, Head We introduce Diffportrait360, a novel approach generates fully consistent 360-degree head views, accommodating human, stylized, and anthropomorphic forms, including accessories like glasses. |
|

|
Yuming Gu, You Xie, Hongyi Xu, Guoxian Song, Yichun Shi, Di Chang, Jing Yang, Linjie Luo. CVPR, 2024 (Highlight - Top 9.3%) [PDF][Page][Code] Area: Novel View Synthesis, Diffusion Model, Face We present DiffPortrait3D, a conditional diffusion model that is capable of synthesizing 3D-consistent photo-realistic novel views from as few as a single in-the-wild portrait. |
|
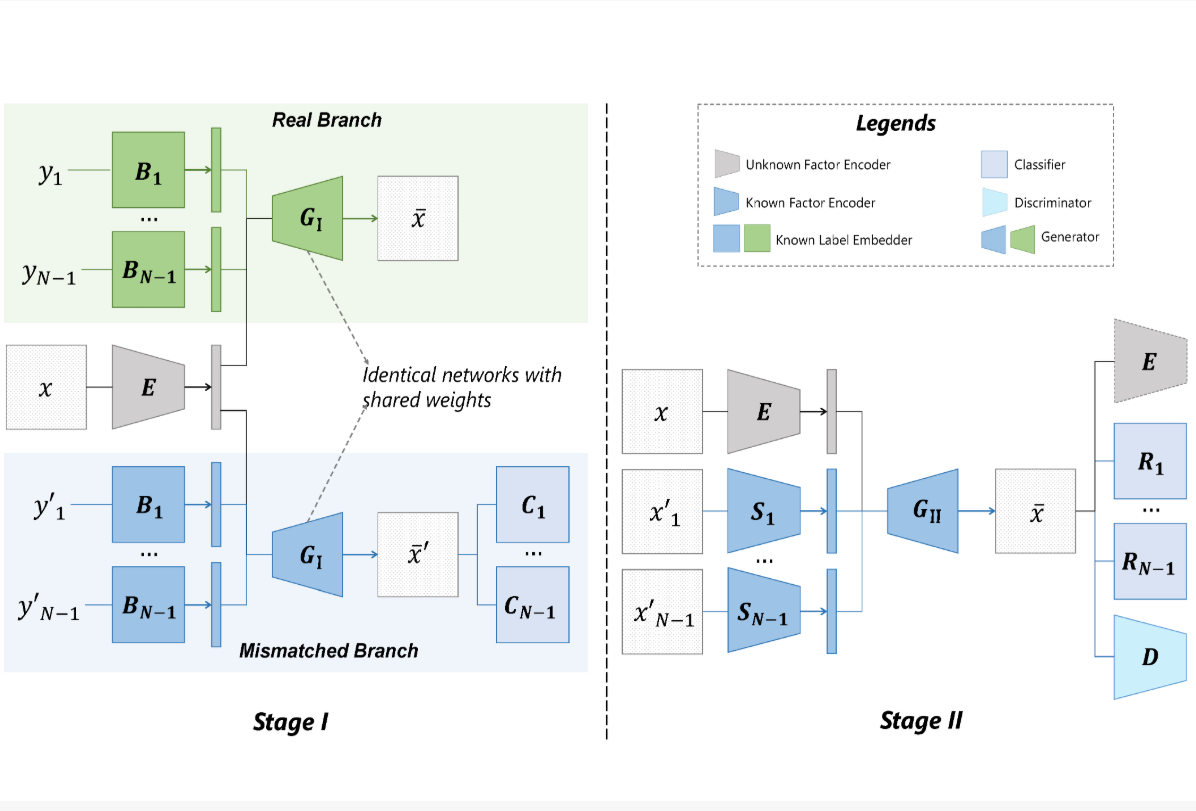
Sitao Xiang, Yuming Gu, Pengda Xiang, Menglei Chai, Hao Li, Yajie Zhao, Mingming He ICCV, 2021 [PDF] [Page] [Code] Area: Disentanglement, neural feature We adopt a general setting where all factors that are hard to label or identify are encapsulated as a single unknown factor. |

|
Sitao Xiang, Yuming Gu, Pengda Xiang, Mingming He, Koki Nagano, Haiwei Chen, Hao Li arixv preprint, 2020 [PDF] Area: Image systhesis, human face We present a deep learning-based framework for portrait reenactment from a single picture of a target (one-shot) and a video of a driving subject. |

|
Shruti Agarwal, Hany Farid, Yuming Gu, Mingming He, Koki Nagano, Hao Li Computer Vision and Pattern Recognition (CVPR workshops), 2019 [PDF] Area: Image systhesis, Media Forensics we describe a forensic technique that models facial expressions and movements that typify an individual's speaking pattern. |
|
|