Abstract
We present DiffPortrait3D, a conditional diffusion model that is capable of synthesizing 3D-consistent photo-realistic novel views from as few as a single in-the-wild portrait. Specifically, given a single RGB input, we aim to synthesize plausible but consistent facial details rendered from novel camera views with retained both identity and facial expression. In lieu of time-consuming optimization and fine-tuning, our zero-shot method generalizes well to arbitrary face portraits with unposed camera views, extreme facial expressions, and diverse artistic depictions. At its core, we leverage the generative prior of 2D diffusion models pre-trained on large-scale image datasets as our rendering backbone, while the denoising is guided with disentangled attentive control of appearance and camera pose. To achieve this, we first inject the appearance context from the reference image into the self-attention layers of the frozen UNets. The rendering view is then manipulated with a novel conditional control module that interprets the camera pose by watching a condition image of a crossed subject from the same view. Furthermore, we insert a trainable cross-view attention module to enhance view consistency, which is further strengthened with a novel 3D-aware noise generation process during inference. We demonstrate state-of-the-art results both qualitatively and quantitatively on our challenging in-the-wild and multi-view benchmarks.
Results
1.Extreme Style


2.Extreme Appearance


3.Extreme Expression


Visualization of Novel View Synthesis Result. DiffPortrait3D shows superior generalization capability to novel view synthesis of wild portraits with unseen appearances, expressions and styles, even without any reliance on fine-tuning.
Architecture
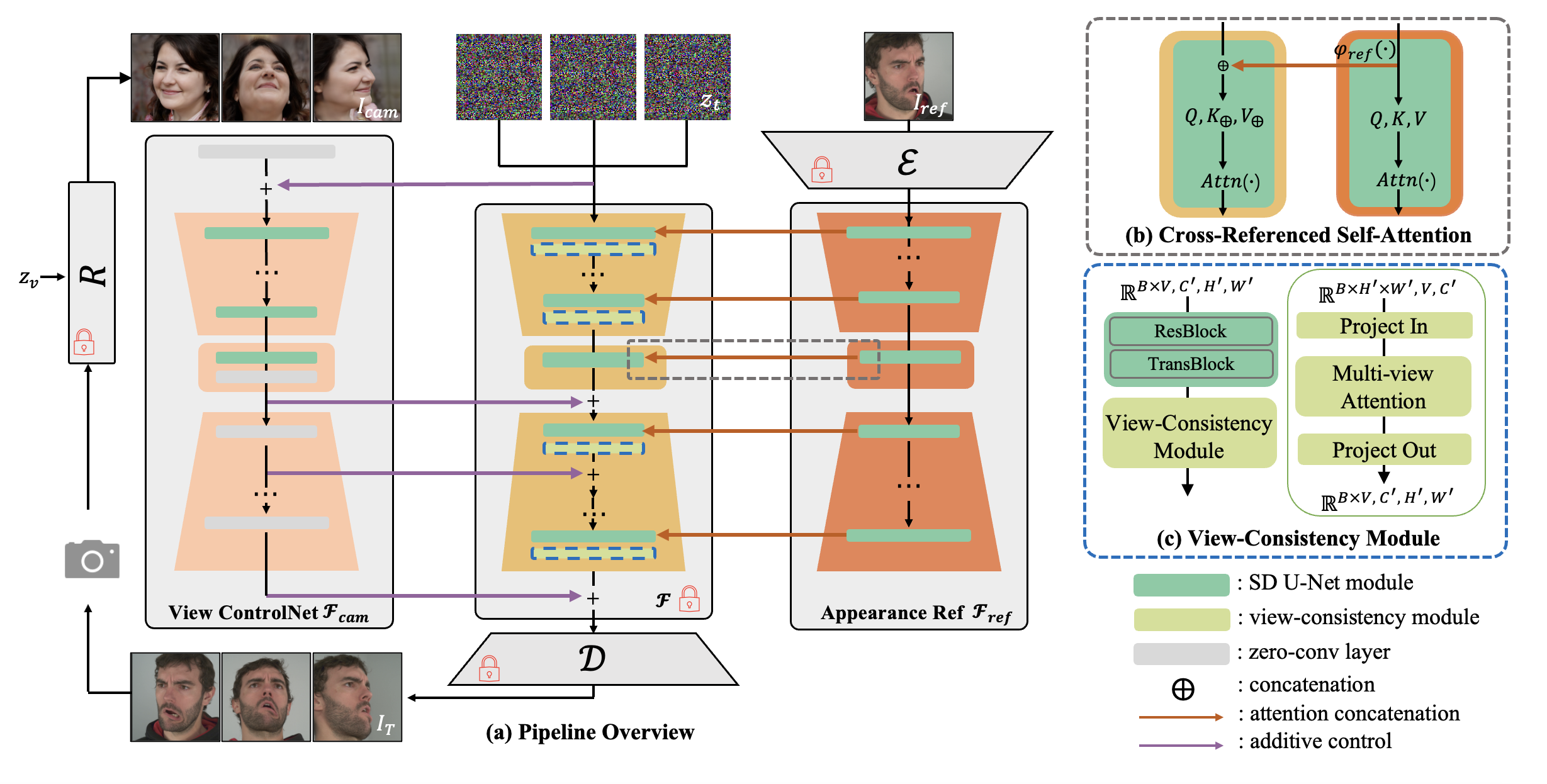
Given a single reference image, we aim to synthesize its novel views at camera perspectives aligned with condition images. We leverage a pre-trained LDM as our image synthesis backbone, where its self-attention layers cross query the appearance context from image via our appearance reference module. Our view control module derives additive view condition from image camera. Additionally, we plug in view consistency modules to enhance multi-view coherence. During training, the images are rendered using an off-the-shelf 3D GAN renderer, where its camera perspectives are aligned.